
A while go someone asked me some questions about Qdrant and how to optimize it’s usage for use case that they were having separate document sets for each “client”. When doing searches, they wanted to search only the documents belonging to the client doing the search.
One of the things that we discussed was whether it’s better to have a single collection for all documents and use a field “client_id” for filtering the results, or to use a separate collection for each client.
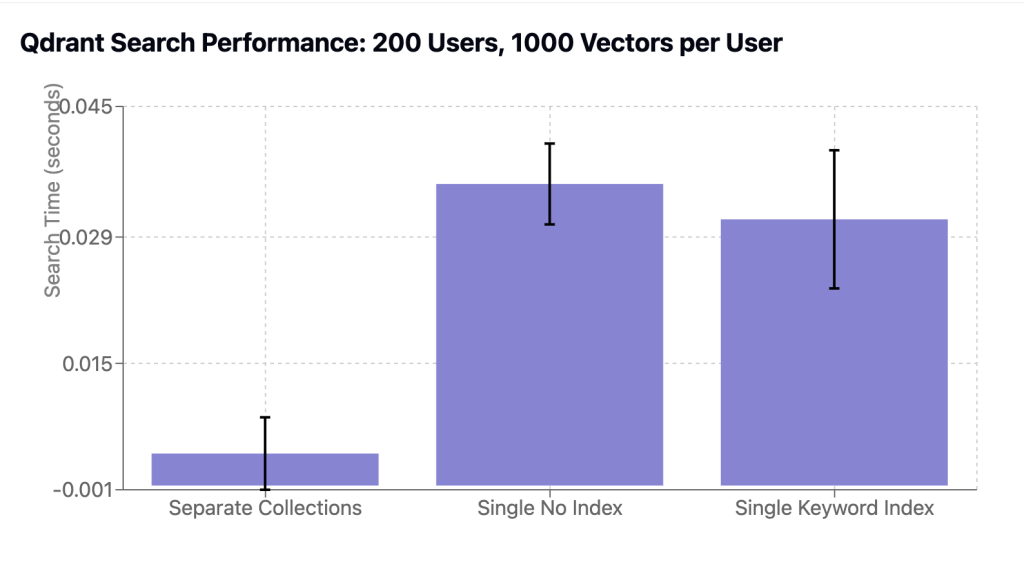
So I wrote a quick benchmark for this (with my friend Claude of course) to compare these scenarios. In the case of single collection, I tested both without an index and with a keyword index on the “client_id” field.
| Configuration | Search Time (ms) | Standard Deviation (ms) |
|---|---|---|
| Separate Collections | 3.8 | 4.3 |
| Single Collection (no index) | 35.8 | 4.8 |
| Single Collection (keyword index) | 31.6 | 8.2 |
Turns out using separate collections is much faster and this holds even for much larger values of users (I tested up to 2000).
Why could that be?
- No Filtering Overhead: When using separate collections, there’s no need to filter results by user_id – you’re already querying the correct subset of data.
- Smaller Search Space: Each collection contains only the vectors for a single user, so Qdrant needs to scan through less data during the search.
- Better Cache Utilization: With separate collections, the index structures for frequently accessed users are more likely to stay in memory.
Of course this isn’t a very comprehensive benchmark. There are many other options you can try out, such as the quite recently introduced tenant index. And having things in a single collection has some other advantages, including some operational ones. Reach out to me if you need help with managing Qdrant for your RAG use cases.
You can find the code to reproduce this in this repo.