Everyone is hyping up GPT-4, and it’s true that it’s currently the best publicly available model. However, numerous open-source models are available that, when well utilized, can perform impressively using significantly fewer resources than GPT-4 (which is actually rumored to be a combination of eight models).
Recently, I completed a ‘talk to your document’ project for a client. There’s no shortage of startups doing this, but this client had an extra security and privacy requirement – their data could not leave their network. Thus, all processing had to happen on-premise. I informed them upfront that the inability to use GPT-4 might result in less accurate results, but they were willing to make that trade-off.
To my surprise, some open-source models proved to be extremely effective for this use case. Specifically, I created the embeddings using DistilBERT models trained on the MS Marco dataset, with FastChat-T5 as a Language Model (LM) for formulating answers.
The resulting system performed exceptionally well. The client was delighted with the performance, and importantly, the entire setup remained on-premise with no data leaving their infrastructure. Also, I was very pleasantly surprised by FastChat, which is a 3 Billion parameter model, but still answers very coherently, while being fast enough to run on a (beefy) CPU only instance!
While GPT-4 is a remarkable model, for companies with high security requirements, there exist various viable alternatives. Despite different trade-offs, these models can still provide excellent performance across a variety of tasks, and I can help you navigate those tradeoffs.
Reach out to me if you would like to have a private and secure “talk to your document” style app for your company!
Machine learning (ML) has exploded in the last decade. Most companies try to apply ML in all kinds of areas, from image processing problems (such as recognizing defects in manufacturing), to forecasting, to trying to extract meaning from unstructured text, and many other problems. A quite common task is that of trying to classify documents into various classes. For example, you have many news articles and you want to group them by their topics, such as politics, entertainment, health, sports and travel. Another example would be a company that has many documents and wants to classify them by their type: invoices, resumes, various reports, and so on.
One of the big challenges of machine learning is that it requires a lot of annotated data. It’s not enough to just get a lot of news articles, a human has to go and annotate at least several thousands of them with their topic and only then can you start applying ML algorithms to solve your problem. In general, the more annotated data points you have, the better accuracy you get.
But getting the data is time-consuming and expensive. In some cases, you can crowdsource the data gathering, using a service such as Mechanical Turk, but in other cases, where more business domain knowledge is needed, the data annotation has to happen in house. If reading and classifying a document takes one minute, then annotating ten thousand documents will take 160 hours, so a month of full time work for someone. To ensure that your labels are accurate, because even human labelers make mistakes, the documents should be labeled by at least three humans. So the costs quickly go up.
SentenceBERT to the rescue
Recent developments in Natural Language Processing (NLP) research have led to the creation of neural networks that have a good understanding of language out of the box. One of them in particular can be used, with a clever reframing of the problem, to solve, or at least make it easier, our problem of text classification.
SentenceBERT is a followup to BERT, making it better by using siamese networks, and is used to generate sentence embeddings. None of this makes any sense? No problem, you don’t need to understand it to get started with it, but I’ll still try to explain the gist of it.
(For some reason, many models in NLP are named after Sesame Street characters: ELMo, BERT, Rosita, ERNIE, Grover, KERMIT, Big BIRD 😄)
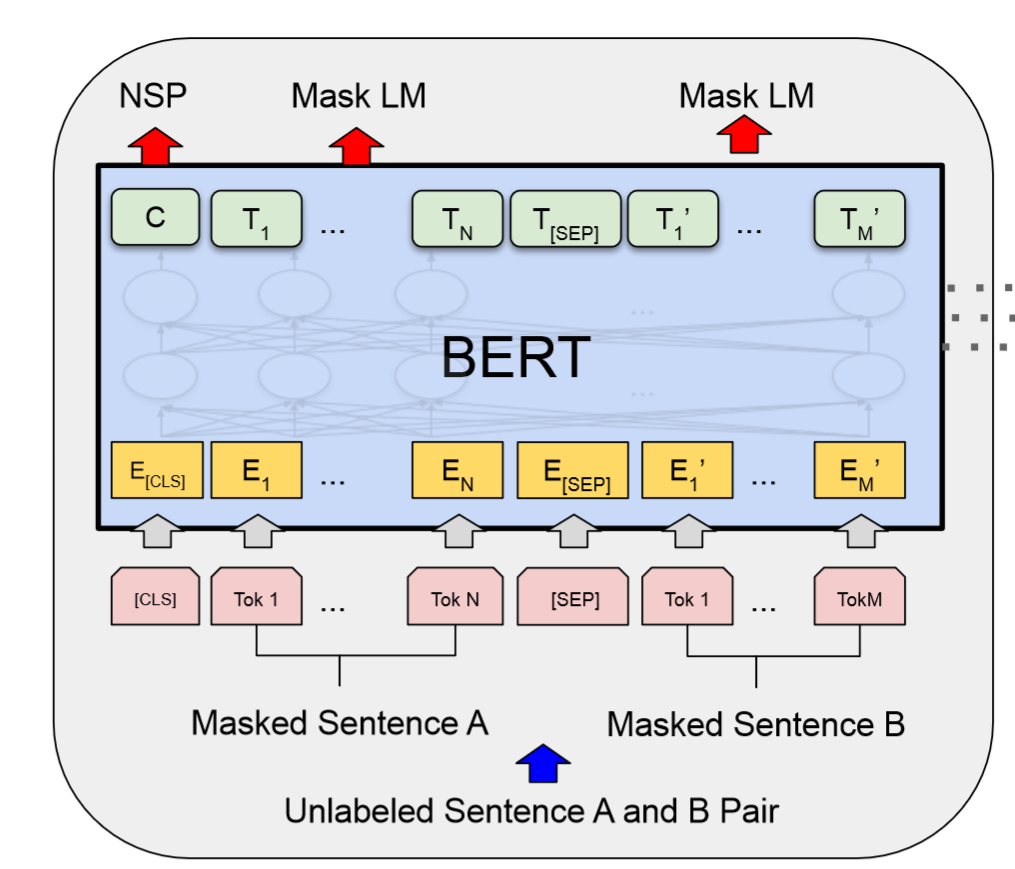
Figure 1: BERT model
The problem SentenceBERT is trained to solve is Natural Language Inference (NLI), which consists of having two sentences, a premise and a hypothesis, and the model has to say what’s the relationship between those two sentences. Does the premise entail the hypothesis, are they neutral (unrelated) or are they contradictory? For example “A soccer game with multiple males playing.” entails “Some men are playing a sport.”, but “A man inspects the uniform of a figure in some East Asian country.” contradicts “The man is sleeping.”.
A side effect of trying to solve this problem is that SentenceBERT learns to “understand” sentences quite well. Understanding sentences is quite a philosophical debate, but what I mean by this is that it reduces a sentence (or even a paragraph) to a vector of numbers, such that sentences that are similar in meaning to each other have similar vectors assigned to them. These vectors are called embeddings and then can enable us to compare sentences.
How does this help us? Remember, we wanted to do text classification of single documents, not to figure out the relationship between two documents. Well, some clever researchers from the University of Pennsylvania have found a clever way to reframe one problem into the other.
Let’s say you want to classify news articles into topics such as politics, entertainment, health, sports, and travel. You take each topic and construct a sentence like “This text is about politics”. Now, this is a NLI problem: does the article entail our artificial sentence, which contains our topic?
It’s a very simple and incredible idea, but it turns out quite well in practice.
Let’s put it into practice
We are going to use the Transformer library from an awesome company called HuggingFace 🤗. They provide a pipeline that does all this for us, so it’s quite simple to use in 6 lines:
from transformers import pipeline
classifier = pipeline("zero-shot-classification", device=0)
sequence = "Who are you voting for in 2020?"
candidate_labels = ["politics", "public health", "economics"]
result = classifier(sequence, candidate_labels)
print(result)
And the output is:
{'labels': ['politics', 'economics', 'public health'],
'scores': [0.972518801689148, 0.014584126882255077, 0.012897057458758354],
'sequence': 'Who are you voting for in 2020?'}
In this simple example, the question “Who are you voting for in 2020?” was classified as being about politics with 97% probability, economics 1.4% probability, and public health as 1.2% probability, so it got this example correctly.
Running this requires a GPU and having all the libraries installed. It’s not hard to set up everything on your own computer, but it works better out of the box on Colab, a free environment Google provides for running Python notebooks in the cloud. You can even request to use a GPU in Colab. A more detailed notebook about this can be found here.
If you want to try it out even simpler, without having to mess around with notebooks, HuggingFace offers a demo on their website, where you just paste in different texts and the list of labels and it classifies them for you.
Other languages
All I presented above was for texts in English. But the same approach can work for other languages as well! There are pretrained models that are tuned for other languages, such as the xlm-roberta-large-xnli. This model supports 100 different languages, including Romanian. In general, results are best in the English language, because that’s where most of the data is (The XLM Roberta model was trained on 300 GB of English texts) and where most of the research has been focused, but even for Romanian language there is a dataset of 60Gb for training, so that should be enough getting things started.
When to use this
As I mentioned before, this is best run on GPUs. You can run it on CPUs, but it will be much slower (10-20 times slower). The more labels you have, the slower it is. It’s a quite complicated model, so it takes a lot of resources.
For text classification, there are many other models that are simpler, faster, and cheaper to run. But they have the disadvantage of requiring annotated data. If you have it, try to use those.
But if for example you are prototyping an idea for a startup and you don’t have annotated data yet, this approach is very good to get you started. In the beginning, you will not have many documents to classify anyway, so the fact that it’s slower is not too problematic, and it will help you quickly validate your idea. If it works, you can then invest in gathering annotated data and then switch to a simpler model.
Another way this model can help is by bootstrapping the annotation process. You have a large set of documents without labels, you run this model over them to generate labels, which might have only 50% accuracy. Then the human labelers only have to verify the suggested labels, thus speeding up the annotation process.
Conclusion
6 years ago, computer vision had it’s so-called “ImageNet” moment, when the challenge of labeling objects in images was “solved”. A new model was presented then which blew away all previous models. NLP is now getting closer to such a moment, with models such as SentenceBERT. In this article, I presented only how to use them for text classification, but they have many other use cases, such as finding similar articles, paraphrase mining, and so on.