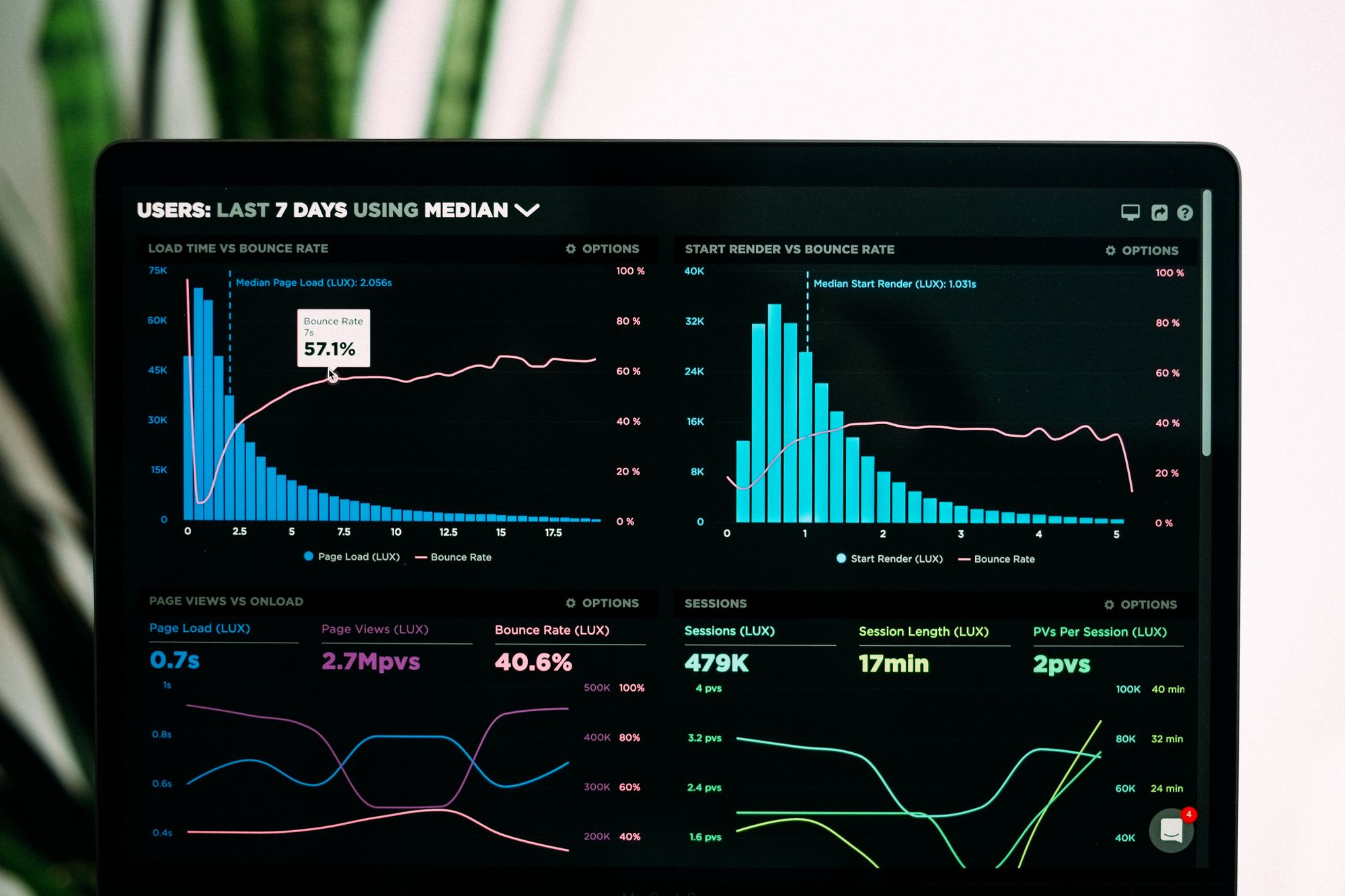
As much as machine learning developers like to think that once they’ve got a good enough model and they deployed it, the job is done, it’s not quite so.
The first couple of weeks after deployment are critical. Is the model really as good as offline tests said they are? Maybe something is different in production then in all your test data. Maybe the data you collected for offline predictions includes pieces of data that are not available at inference time. For example, if trying to predict click through rates for items in a list and use that to rank the items, when building the training dataset it’s easy to include the rank of the item in the data. But the model won’t have that when making predictions, because it’s what you’re trying to infer. Surprise, the model will perform very poorly in production.
Or maybe simply A/B testing reveals that the fancy ML model doesn’t really perform better in production than the old rules written with lots of elbow grease by lots of developers and business analysts, using lots of domain knowledge and years of experience.
But even if the model does well at the beginning, will it continue to do so? Maybe there will be an external change in user behavior and they will start searching for other kinds of queries, which your model was not developed for. Or maybe your model will introduce a “positive” feedback loop: it suggests some items, users click on them, so those items get suggested more often, so more users click on them. This leads to a “rich get richer” kind of situation, but the algorithm is actually not making better and better suggestions.
Maybe you are on top of this and you keep retraining your model weekly to keep it in step with user behavior. But then you need to have a staggered release of the model, to make sure that the new one is really performing better across all relevant dimensions. Is inference speed still good enough? Are predictions relatively stable, meaning we don’t recommend only action movies one week and then only comedies next week? Are models even comparable from one week to another? Or is there a significant random component to them which makes it really hard to see how they improved? For example, how are the clusters from the user post data built up? K-means starts with random centroids and clusters from one run have only passing similarity to the ones from another run. How will you deal with that?








