Data is crucial to any machine learning effort. And not just any data, but annotated data, so that the machine learning algorithms can learn what is the outcome it should predict. In some cases, we can get the data from some existing processes in the business, but more often than not, we need to set up a manual annotation process.
For annotating freeform text data (text generated by people) there is a great open source tool called Doccano. It is used to gather data for a wide range of common natural language processing (NLP) tasks, such as sentiment analysis, document classification, named entity recognition (NER), summarization, question answering, translation and others.
Text Annotation types
There are three kinds of data annotation types in Doccano.
Text classification
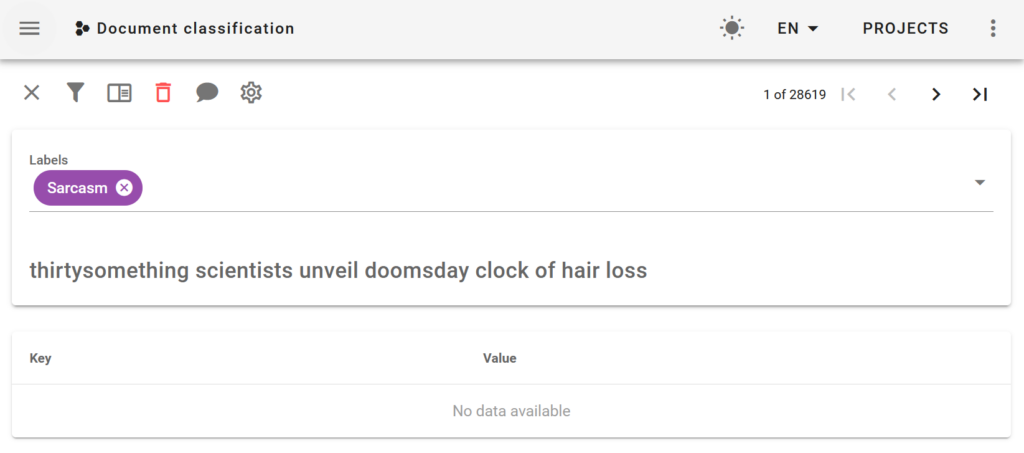
This kind of project enables you to annotate labels that apply to the entire document. For example, in a sentiment analysis task, you could label a document as being positive or negative. In a document classification task you will annotate what’s the topic of the document. You can choose multiple labels for each document.
Sequence Labeling
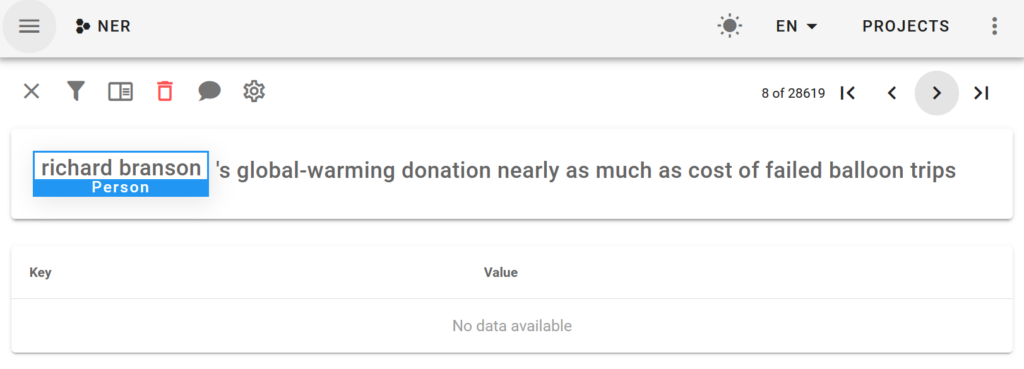
This is generally used for NER tasks, where you select relevant fragments from the text. For example, where are persons or organizations mentioned in documents. There can be several fragments selected for each document.
Sequence to Sequence
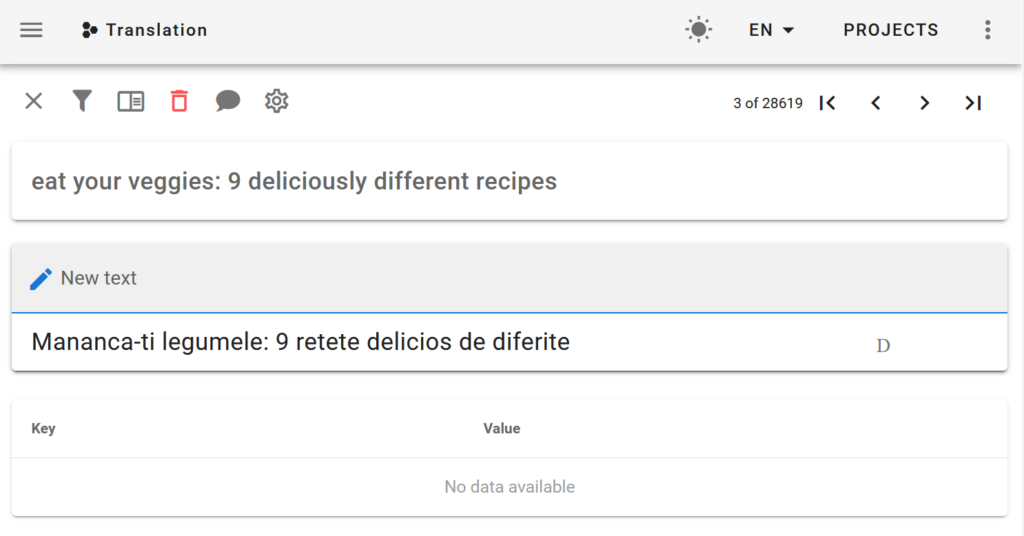
The Seq2seq annotation is for tasks such as summarization, question answering or translations from one language to another. There is a text box where you can write the appropriate response. For summarization, this would be the summary of the document. For questions, you can write several answers.
Setting up Doccano
Doccano offers 1-click installs for AWS, Azure and Heroku, or you can run it locally using Docker.
After you have Doccano running, you must create a new project and import your documents. Doccano is quite flexible and you can import data in multiple formats, such as plain text, CSV, JSONL or even fastText format.
You can create multiple users who will work on annotation. They can review each others work or they can annotate independently each document. In this case, the annotations from different labelers can be compared. If there are big differences, maybe the task is not clear and better guidelines are needed – if humans can’t solve the problem, machine learning won’t be able to solve it either.
Doccano features
Doccano is trying to make the annotation workflow as efficient as possible by giving keyboard shortcuts for most actions.
It has a dashboard where you can see statistics about how many documents were annotated, what’s the frequency of labels and how many documents were processed by each labeler.
You can also speed up the process by using an existing machine learning model to bootstrap the annotations. Either when uploading the data you specify some existing labels or you can configure Docanno to make a call to another REST API and get annotations from there. Then the labelers only have to review the output of the algorithm, instead of annotating from scratch.
Text Annotation Alternatives
There are other annotation tools as well. One for example is Prodigy, from the makers of Spacy, one of the most popular NLP libraries. It has a tight integration with Spacy and it has support for active learning, but it’s a paid product, unlike Doccano.
Another option is Label Studio, which supports annotating images, audio and time series, not just text.
If you need help setting up a text annotation pipeline to make sure that you are gathering the right data for your problem, don’t hesitate to contact me.