Everyone is hyping up GPT-4, and it’s true that it’s currently the best publicly available model. However, numerous open-source models are available that, when well utilized, can perform impressively using significantly fewer resources than GPT-4 (which is actually rumored to be a combination of eight models).
Recently, I completed a ‘talk to your document’ project for a client. There’s no shortage of startups doing this, but this client had an extra security and privacy requirement – their data could not leave their network. Thus, all processing had to happen on-premise. I informed them upfront that the inability to use GPT-4 might result in less accurate results, but they were willing to make that trade-off.
To my surprise, some open-source models proved to be extremely effective for this use case. Specifically, I created the embeddings using DistilBERT models trained on the MS Marco dataset, with FastChat-T5 as a Language Model (LM) for formulating answers.
The resulting system performed exceptionally well. The client was delighted with the performance, and importantly, the entire setup remained on-premise with no data leaving their infrastructure. Also, I was very pleasantly surprised by FastChat, which is a 3 Billion parameter model, but still answers very coherently, while being fast enough to run on a (beefy) CPU only instance!
While GPT-4 is a remarkable model, for companies with high security requirements, there exist various viable alternatives. Despite different trade-offs, these models can still provide excellent performance across a variety of tasks, and I can help you navigate those tradeoffs.
Reach out to me if you would like to have a private and secure “talk to your document” style app for your company!
Like everyone else, I’ve been playing a lot with ChatGPT, sometimes asking various questions, but mostly coding related stuff. I tried to replicate the experience some people report on Twitter of coding entire apps with ChatGPT and having it fix all the errors that show up. My experience has been more of a whack-a-mole, where I tell it to fix something and then it introduces another bug, or omits an endpoint, and after 10 minutes of this I just go fix it myself. I find that the claims that ChatGPT is the future of coding are somewhat overblown.
But I also used it in a slightly different way, by starting to define a web app that does what I want and then changing the storage layer. First I started off with Deta (free “cloud” for personal projects), then I asked it to move to SQLite. And for this kind of stuff, it does a pretty good job. However, I do have to review all the code and I inevitably run into bugs and regressions.
Using ChatGPT to replace ORMs
But normally, changing the storage layer is a long and boring work: even if you are just switching between various SQL databases, you have to make sure that you were not using some particular database specific language construct or that you were not relying on some implicit ordering in one flavour that doesn’t exist in another one. And this is part of the reason why things like ORMs have come into existence: to abstract away all the differences between SQL databases and allow you to easily change from one to another (with the caveat that it’s still a bad idea once you’re in production and it will most likely result in performance issues).
But if I can just have my AI assistant (be it ChatGPT, Github Copilot, or any other LLM based tool) rewrite all the SQL code (or even move to a NoSQL database), I don’t particularly care about that higher level of abstraction anymore. I’ll just ask Copilot to migrate from MySQL to Postgres, generate the new better indices and use built-in ARRAY columns instead of the normalized tables I used in MySQL (just to give an example).
Making design patterns obsolete
And I’m thinking that maybe in the future many of the coding best practices that exist today won’t be relevant anymore. For example, normally you want to avoid writing duplicate code because if you have to change something in the future, you don’t want to have to change in multiple places (because we programmers are lazy) and because we might forget to change in all the places (so some duplicate code might not be changed so we might introduce bugs). But if I can ask Copilot to change this code pattern wherever it appears, I might not even want to do that anymore, because sometimes code is easier to read if you don’t have to jump between several functions all the time. And Copilot can be really smart about it, changing not only in places where it appears exactly the same way, but also in places where there are some small differences (which are unrelated to the change we proposed).
Previously, this was a problem: if I have a piece of code repeated 5 times, but with small differences in each, do I extract them into a common function, with lots of ifs? Do I create some complicated class hierarchy that allows me to reuse common functionality and to customize the differences? Or do I just simply leave things duplicated and hope I will fix all bugs when they appear? With ChatGPT, that tradeoff might no longer be necessary.
Another quite common pattern (in some programming languages) is dependency injection, which allows you to define at runtime where a certain dependency comes from. In my experience, you rarely want to fiddle with that, with one big exception: testing. Dependency injection makes testing a lot easier, especially in more statically typed languages (Java, C#, etc). But what if, when pushing the “Run test” button in the IDE, ChatGPT could change all the relevant database connections (for example) from the big SQL server to an in-memory database? Then you wouldn’t have to look at ugly dependency injection code and scratch your head to figure out where the heck did a certain value come from.
The future of coding
This is still far off in the future. ChatGPT is still too unreliable to do this at scale. But lots of people are exploring using LLMs for the future of coding (such as Geoffrey Litt) and maybe the next level of programming will be to have some sort of high level templates that we feed to ChatGPT which will spit out code at “build time”. We will be able to tell it that we want to read the code, so it will output something that is easier for humans to read and understand, or we can specify that the target is the computer, so it will output something that can be compiled efficiently.
Of course this will require several things first: having ChatGPT create a test suite first, so that you can verify that the changes are working reliably, finding a good temperature for it to generate code without becoming too creative, and finding a way to work with large codebases (even the new 32K tokens context size is not enough for more than tens of files, and I don’t think the current way of working with embeddings is very good either).
But I believe we have some exciting new ways of working ahead of us! So let’s explore the future of coding!
Image at the top brought to you by DALL-E2 and proofreading done by ChatGPT.
Let’s take a look at how to do multi label text classification with Spacy. In multi label text classification each text document can have zero, one or more labels associated with it. This makes the problem more difficult than regular multi-class classification, both from a learning perspective, but also from an evaluation perspective. Spacy offers some tools to make that easy.
spaCy
Spacy is a great general purpose NLP library, that can be used out of the box for things like part of speech tagging, named entity recognition, dependency parsing, morphological analysis and so on. Besides the built-in modules, it can also be used to train custom models, for example for text classification.
Spacy is quite powerful out of the box, but the documentation is often lacking and there are some gotchas that can prevent a model from training, so below I am writing a simple guide to train a simple multi label text classification model with this library.
Training data format
Spacy requires training data to be in its own binary data format, so the first step will be to transform our data into this format. I will be working with the lex_glue/ecthr_a dataset in this example.
First, we have to load the dataset.
from datasets import load_dataset
dataset = load_dataset("lex_glue", 'ecthr_a')
print(dataset)
print(dataset['train'][0])
Which will output the following:
DatasetDict({
train: Dataset({
features: ['text', 'labels'],
num_rows: 9000
})
test: Dataset({
features: ['text', 'labels'],
num_rows: 1000
})
validation: Dataset({
features: ['text', 'labels'],
num_rows: 1000
})
})
{'text': ['11. At the beginning of the events relevant to the application, K. had a daughter, P., and a son, M., born in 1986 and 1988 respectively. P.’s father is X and M.’s father is V. From March to May 1989 K. was voluntarily hospitalised for about three months, having been diagnosed as suffering from schizophrenia. From August to November 1989 and from December 1989 to March 1990, she was again hospitalised for periods of about three months on account of this illness. In 1991 she was hospitalised for less than a week, diagnosed as suffering from an atypical and undefinable psychosis. It appears that social welfare and health authorities have been in contact with the family since 1989.',
'12. The applicants initially cohabited from the summer of 1991 to July 1993. In 1991 both P. and M. were living with them. From 1991 to 1993 K. and X were involved in a custody and access dispute concerning P. In May 1992 a residence order was made transferring custody of P. to X.',
....
'93. J. and M.’s foster mother died in May 2001.'],
'labels': [4]}
The dataset comes with a train, validation and test split. The documents themselves are split into multiple paragraphs and the labels are just integers, not the actual string descriptions of labels. The actual labels are:
To transform a single document into the DocBin format, we have to parse the combined paragraphs with Spacy and add all the labels to the document. The parsing we do here is not very important, so we can use the smallest English model from Spacy.
import spacy
nlp = spacy.load("en_core_web_sm")
d = dataset['train'][0]
text = "\n\n".join(d['text'])
doc = nlp(d)
for l in labels:
if l in d['labels']:
doc.cats[l] = 1
else:
doc.cats[l] = 0
print(doc[:10])
print(doc.cats)
Which will output:
11. At the beginning of the events relevant
{'Article 2': 0, 'Article 3': 0, 'Article 5': 0, 'Article 6': 0, 'Article 8': 0, 'Article 9': 0, 'Article 10': 0, 'Articl
e 11': 0, 'Article 14': 0, 'Article 1 of Protocol 1': 0}
One gotcha that I ran into was that you have to specify all the labels for each document (unlike with Fasttext): the ones that are for this document with “probability” 1, and the ones that are not applied with “probability” 0. Spacy won’t give any errors (unlike scikit-learn) if you don’t do this, but the model will not train and you will always get an accuracy of 0.
The above snippet can be made more efficient by using the built-in pipeline from Spacy, which processes documents in batches, but we will have to go over the documents twice, once to build up the list of joined paragraphs (which Spacy can process) and once to add the labels.
from spacy.tokens import DocBin
from tqdm import tqdm
for t, o in [(dataset['train'], "ecthr_train.spacy"), (dataset['test'], "ecthr_dev.spacy")]:
db = DocBin()
docs = []
cats = []
print("Extracting text and labels")
for d in tqdm(t):
docs.append("\n\n".join(d['text']))
cats.append([labels[idx] for idx in d['labels']])
print("Processing docs with spaCy")
docs = nlp.pipe(docs, disable=["ner", "parser"])
print("Adding docs to DocBin")
for doc, cat in tqdm(zip(docs, cats), total=len(cats)):
for l in labels:
if l in cat:
doc.cats[l] = 1
else:
doc.cats[l] = 0
db.add(doc)
print(f"Writing to disk {o}")
db.to_disk(o)
Generating the model config
Spacy has it’s own config system for training models. You can generate a config with the following command:
> spacy init config --pipeline textcat_multilabel config_efficiency.cfg
Generated config template specific for your use case
- Language: en
- Pipeline: textcat_multilabel
- Optimize for: efficiency
- Hardware: CPU
- Transformer: None
✔ Auto-filled config with all values
✔ Saved config
config_eff.cfg
You can now add your data and train your pipeline:
python -m spacy train config_effiency.cfg --paths.train ./train.spacy --paths.dev ./dev.spacy
By default, it uses a simple bag of words model, but you can set it to use a bigger convolutional model:
One thing that I usually change in the generated config is the logging system. I either enable the Weight and Biases configuration (which requires wandb to be installed in the virtual environment) or at least enable the progress bar:
You can modify any of the hyperparameters of the pipeline here, such as optimizer type or the ngram_size of the model, which is 1 by default (and I usually increase it to 2-3).
Another thing you can set here is how should Spacy determine the best model at the end of training. You can weight the different metrics: micro/macro recall/precision/f1 scores. By default it looks only at the F1 score. Setting this depends very much on what problem you are trying to solve and what is more important from a business perspective.
And now we have two models in the ecthr_model folder: the last one and the one that scored best according to the metrics defined in the config file.
Using the trained model
To use the model, load it in your inference pipeline and use it like any other Spacy model. The only difference will be that the resulting Doc object will have the cats attribute filled with the predictions for your multilabel classification problem.
The output is the probability for each class. The model was trained with a threshold of 0.5, so it would consider only “Article 11” to be applied to this document, but you can choose a different threshold if you want a different precision/recall balance.
Cons of Spacy
Training is slow. Even the efficient architecture, which uses an n-gram bag of words model (with a linear layer on top, I guess) trains in half an hour. In contrast, scikit-learn can train a logistic regression in minutes.
Documentation has gaps: you often have to dig into the source code of Spacy to know exactly what is going on. And searching the internet is not always helpful, because there are many outdated answers and tutorials, which were written for previous versions of Spacy and are no longer relevant.
Conclusion
Spacy is another library that can be used to start training text classification models. It’s particularly great if you are already using it for some of the other things it provides, because then you need fewer dependencies and that can simplify your model maintenance and deployment.
Prodigy is a great tool for annotating the datasets needed to train machine learning models. It has built in support for many kinds of tasks, from text classification, to named entity recognition and even for image and audio annotation.
One of the cool things about Prodigy is that it integrates with Spacy (they are created by the same company), so you can use active learning (having a model suggest annotations and then being corrected by humans) or you can leverage Spacy patterns to automatically suggest annotations.
Prodigy has various recipes for these things, but it doesn’t come with a recipe to use only patterns for manual annotation for a multilabel text classification problem, only in combination with an active learning loop. The problem is that for multi-label annotation, Prodigy does binary annotation for each document, meaning the human annotator will be shown only one label at a time and they’ll have to decide if it’s relevant to the document or not. If you have many labels, it means each document might be shown as many times as there are labels.
I recently had to solve a problem where I knew that most of the documents would have a single label, but in a few cases there would be multiple labels. I also had some pretty good patterns to help bootstrap the process, so I wrote a custom recipe that used only patterns for a multilabel text classification problem.
Code for custom recipe
To do this, I combined some code from the recipes that are provided by Prodigy for text categorization. Let’s see how it work.
First, let’s define the CLI arguments in a file called manual_patterns.py. We’ll need:
@recipe(
"textcat.manual_patterns", # Name of the recipe
dataset=("Dataset to save annotations to", "positional", None, str),
source=("File path with data to annotate", "positional", None, str),
spacy_model=("Loadable spaCy pipeline or blank:lang (e.g. blank:en)", "positional", None, str),
labels=("Comma-separated label(s) to annotate or text file with one label per line", "option", "l", get_labels),
patterns=("Path to match patterns file", "option", "pt", str),
)
Then we need to define the function that loads the stream of data, runs the PhraseMatcher on it and returns the project config:
The last bit is the function which takes the suggestions generated by the PhraseMatcher and adds them to be selected by default in the UI. In this way, the annotators can quickly accept them:
def add_suggestions(stream, matcher, labels):
texts = (eg for score, eg in matcher(stream))
options = [{"id": label, "text": label} for label in labels]
for eg in texts:
task = copy.deepcopy(eg)
task["options"] = options
if 'label' in task:
task["accept"] = [task['label']]
del task['label']
yield task
Expected file formats
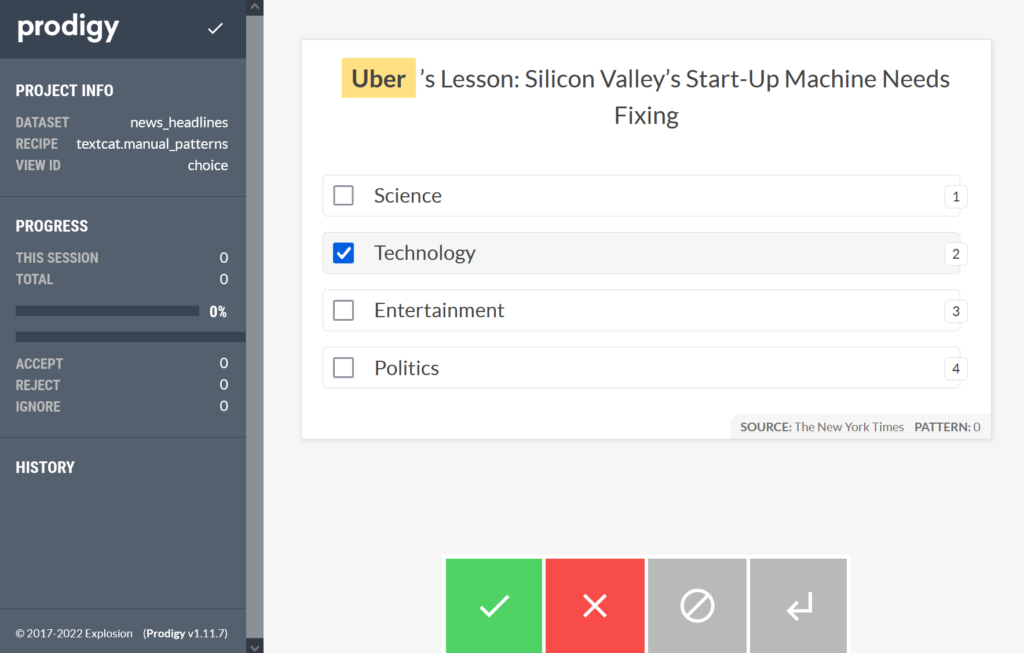
Now let’s run the recipe. Assuming we have an news_headlines.jsonl file in the following format:
{"text":"Pearl Automation, Founded by Apple Veterans, Shuts Down"}
{"text":"Silicon Valley Investors Flexed Their Muscles in Uber Fight"}
{"text":"Uber is a Creature of an Industry Struggling to Grow Up"}
{"text": "Brad Pitt is divorcing Angelina Jolie"}
{"text": "Physicists discover new exotic particle"}
> python -m prodigy textcat.manual_patterns news_headlines news_headlines.jsonl blank:en --label "Science,Technology,Entertainment,Politics" --patterns patterns.jsonl -F .\manual_patterns.py
Using 4 label(s): Science, Technology, Entertainment, Politics
Added dataset news_headlines to database SQLite.
D:\Work\staa\prodigy_models\manual_patterns.py:67: UserWarning: [W036] The component 'matcher' does not have any patterns defined.
texts = (eg for score, eg in matcher(stream))
✨ Starting the web server at http://localhost:8080 ...
Open the app in your browser and start annotating!
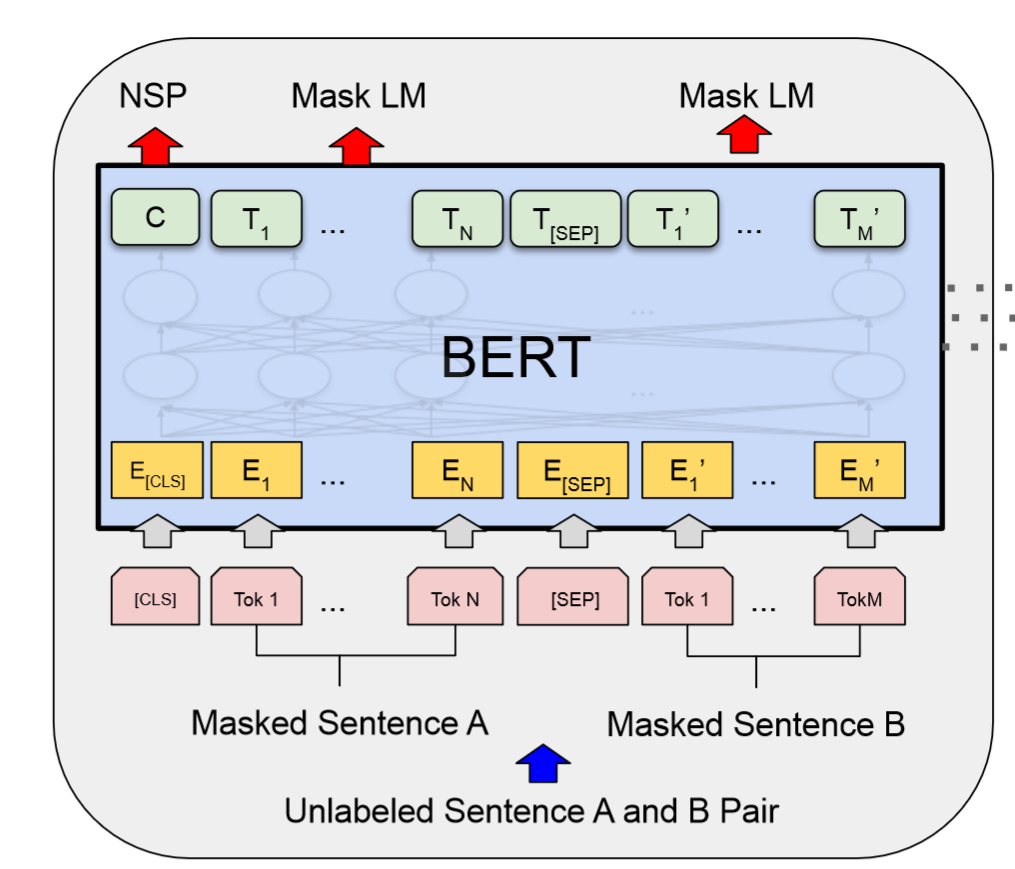
BERT1Bidirectional Encoder Representations (and it’s numerous variants) models have taken the natural language processing field by storm ever since they came out and have been used to establish state of the art results in pretty much all imaginable tasks, including text analysis.
I am a Christian, so the Bible is important to me. So, I became curious to see what BERT would “think” about the Bible. The manuscripts of the Bible on which modern translations are based were written in Hebrew (Old Testament) and Greek (New Testament). There are many difficult challenges in the translation, resulting in many debates about the meaning of some words. I will conduct two experiments on the text of the New Testament to see what BERT outputs about the various forms of “love” and about the distinction between “soul” and “spirit”.
Quick BERT primer
There are many good explanations of how BERTworks and how it’s trained, so I won’t go into that, I just want to highlight two facts about it:
one of the main tasks that is used to train a BERT model is to predict a word2actually a byte pair encoded token given it’s context: “Today is a [MASK] day”. In this case it would have to predict the fourth word and possible options are “beautiful”, “rainy”, “sad” and so on.
one of the things that BERT does really well is to create contextual word embeddings. Word embeddings are mathematical representations of words, more precisely they are high dimensional vectors (768 in the case of BERT), that have a sort of semantic meaning. What this means is that the word embedding similar words is close to each other, for example, the embeddings for “king”, “queen” and “prince” would be close to each other, because they are all related to royalty, even though they have no common lemma. The contextual part means there is no one fixed word embedding for a given word (such as older models like word2vec or GloVe had), but it depends on the sentence where the word is used, so the word embedding for “bank” is different in the sentence “I am going to the bank to deposit some money” than in the sentence “He is sitting on the river bank fishing”, because they refer to different concepts (financial institution versus piece of land).
Obtaining the embeddings
Reading the data
First, let’s read the Bible in Python. I’ve used the American King James Version translation, because it uses modern words and it’s available in an easy to parse text file, where the verse number (Matthew 15:1) is separated from the text of the verse by a tab (\t):
Genesis 1:1 In the beginning God created the heaven and the earth.
verses = {}
with open('akjv.txt', 'r', encoding='utf8') as f:
lines = f.readlines()
for line in lines[23146:]: # The New Testament starts at line 23146
citation, raw_sentence = line.strip().split('\t')
verses[citation] = raw_sentence
The next thing we need is the Strong’s numbers, which are a code for each Greek word (or rather base lemma) that appears in the New Testament. I have found a mapping to tell me the corresponding Strong’s number for (most) English words only for the ESV3I had to rename the New Testament book names and convert the file to UTF8 without BOM translation, which might mean that there are slight differences in verse boundaries, but I don’t think that the words I’m going to be analyzing will be different. Here the format is also verse number, followed by xx=<yyyy> pairs, where xx is the ordinal number for a word in the ESV translation and yyyy is the corresponding Strong’s number.
Matthew 1:1 02=<0976> 05=<1078> 07=<2424> 08=<5547> 10=<5207> 12=<1138> 14=<5207> 16=<0011>
This line says that in Matthew 1:1 the second word in the ESV translation corresponds to the Greek word with Strong’s number 976, the fifth word in English to the word with Strong’s number 1078 and so on. The Strong’s numbers are nicely preformatted into 4 character strings, so we check if a Strong’s number is in a verse by simply looking if the number is in this string, without having to parse each verse.
strongs_tags = {}
with open("esv_tags.txt") as f:
lines = f.readlines()
for line in lines:
verse, strongs = line.split("\t", maxsplit=1)
strongs_tags[verse] = strongs
Getting the embedding for a word with BERT
Let’s load the BERT model and it’s corresponding tokenizer, using the HuggingFace library:
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained('bert-base-cased')
model = model = AutoModel.from_pretrained('bert-base-cased', output_hidden_states=True).eval()
BERT has a separate tokenizer because it doesn’t work on characters or on words directly, but it works on byte pair encoded tokens. For more frequent words, there is a 1:1 mapping of word – token, but rarer words (or words with typos) will be split up into multiple tokens. Let’s see this for the word “love” and for “aardvark”:
[CLS] and [SEP] are two special tokens, mostly relevant during training. The word_ids function returns the index of the word to which that token belongs. Let’s see an example with a rare word:
In this case, aardvarks (the second word) is split up into 4 tokens, which is why it shows up 4 times in the list obtained from word_ids.
Now, let’s find the index of the word we are looking for in a verse:
def get_word_idx(sent: str, word: str):
l = re.split('([ .,!?:;""()\'-])', sent)
l = [x for x in l if x != " " and x != ""]
return l.index(word)
We split on punctuation and spaces, skip empty strings and ones with a space and get the index of the word we are looking for.
Because the BPE encoding can give multiple tokens for one word, we have to get all the tokens that correspond to it:
encoded = tokenizer.encode_plus(sent, return_tensors="pt")
idx = get_word_idx(sent, word)
# get all token idxs that belong to the word of interest
token_ids_word = np.where(np.array(encoded.word_ids()) == idx)
In BERT, the best word embeddings have been obtained by taking the sum of the last 4 layers. We pass the encoded sentence through the model to get the outputs at the last 4 ones, sum them up layerwise and then average the outputs corresponding to the tokens that are part of our word:
def get_embedding(tokenizer, model, sent, word, layers=None):
layers = [-4, -3, -2, -1] if layers is None else layers
encoded = tokenizer.encode_plus(sent, return_tensors="pt")
idx = get_word_idx(sent, word)
# get all token idxs that belong to the word of interest
token_ids_word = np.where(np.array(encoded.word_ids()) == idx)
with torch.no_grad():
output = model(**encoded)
# Get all hidden states
states = output.hidden_states
# Stack and sum all requested layers
output = torch.stack([states[i] for i in layers]).sum(0).squeeze()
# Only select the tokens that constitute the requested word
word_tokens_output = output[token_ids_word]
return word_tokens_output.mean(dim=0)
Processing the New Testament with BERT
Now let’s get the embeddings for the target words from all the verses of the New Testament. We will go through all the verses and if any of the Strong’s numbers appear in the verse, we will start looking for a variation of the target word in English and get the embedding for it. The embedding, the verse text, the Greek word and the book where it appears will be appended to a list.
def get_all_embeddings(greek_words, english_words):
embeddings = []
for key, t in verses.items():
strongs = strongs_tags[key]
for word in greek_words:
for number in greek_words[word]:
if number in strongs:
gw = word
for v in english_words:
try:
if v in t:
emb = get_embedding(tokenizer, model, t, v).numpy()
book = books.index(key[:key.index(" ", 4)])
embeddings.append((emb, f"{key} {t}", gw, book))
break
except ValueError as e:
print("Embedding not found", t)
else:
print("English word not found", key, t)
return embeddings
Next, I am going to take all the verses where one of these target words appear in the New Testament. I am going to mask out their appearance and ask BERT to predict what word should be there.
def mask_and_predict(word_list):
predictions = []
for key, t in verses.items():
for v in word_list:
if v in t:
try:
new_t = re.sub(f"\\b{v}\\b", "[MASK]", t)
top_preds = unmasker(new_t)
if type(top_preds[0]) == list:
top_preds = top_preds[0]
predictions.append((f"{key} {t}", v, top_preds))
break
except Exception:
print(new_t, v)
return predictions
Love
In Greek, there are several words that are commonly translated as love: agape, eros, philia, storge, philautia, xenia, each having a different focus/source. In the New Testament, two of these are used: agape and philia. There is much debate between Christians about the exact meaning of these two words, such as whether agape is bigger than philia, the two are mostly synonyms, or philia is the bigger love.
To try to understand what BERT thinks about these two variants, I am going to extract the 768 dimensional word embeddings for the English word love, reduce their dimensionality with UMAP and plot the results, color coding them by the original word used in Greek.
Now we’ll need the Strong’s numbers for the two words we’re investigating. I included several variations for each word, such as verbs/nouns, or composite variants, such as 5365 – philarguria, which is philos + arguria, meaning love of money.
There are some weird failure cases: in 1 Corinthians 13, famously called the chapter of love, the AKJV uses charity for example instead of love for the Greek word “agape”. I chose to not look for charity as well, so all those uses of “agape” are left out.
Now that we have all the embeddings, let’s reduce their dimensionality with UMAP and then visualize them. They will be color coded according to the Greek word and on hover they will show the verse.
The blue dots are where the Greek is agape (or it’s derivatives), while the red ones are where the Greek is philos.
You can notice 4 clusters in the data. The top right cluster is mostly made out of love that is between Christians. The bottom right one seems to be mostly about the love of God, with the love of money throw in there as well (the blue dot on the right). The cluster on the left seems to be less well defined, with the top side looking like it’s about commandments related to love (you shall love, should love, if anyone will love) and it’s consequences. The bottom left side is the most fuzzy, but I think it seems to be about the practical love of Jesus for humans.
What is easier to notice is that the Greek words agape and philos are mixed together. The love of God cluster (bottom right) seems to be the only one that is agape only (if we exclude the love of money verse, which reeaaaally doesn’t belong with the others), with the exception of the Titus 3:4 verse, which however does sound very much like the others.
However, we can plot the same graph, but this time color coding with the parts of the New Testament where the verse is found:
There is lots of mixing in all clusters, but it seems to me that the Pauline letters use love in a different way then the gospels.
Conclusion? Yes, the word agape does sometimes refer to the love of God, in a seemingly special way, but it often refers to other kinds of love as well, in a way which BERT can’t really distinguish from philos love.
Soul and spirit
The Bible uses two words for the immaterial parts of man: soul (Hebrew: nephesh, Greek: psuche) and spirit (Hebrew: ruach, Greek: pneuma). Again, there is great debate whether the two are used interchangeably or whether they are two distinct components of humans.
After getting the embeddings for these two words, I will plot them as we did before. We can discover quite a few clusters in this way.
In this case, the clusters are almost perfectly separated, with very little mixing. What little mixing happens is usually because in one verse both words occur. Contrast this with the case for agape/phileo, where there is a lot of mixing.
The top right cluster is about the Spirit of God. The one below is about unclean/evil spirits. The middle cluster is about the Holy Spirit. The bottom left cluster is mostly about the spirit of man, with some examples from the other clusters.
The interesting thing is that the two verses used as most common arguments for the soul being distinct from the spirit (1 Thessalonians 5:23 and Hebrews 4:12) are placed in the blue cluster, and they are right next to Matthew 22:37, Mark 12:30 and Luke 10:27, verses which indicate that man is made of different components (heart, soul, mind, strength).
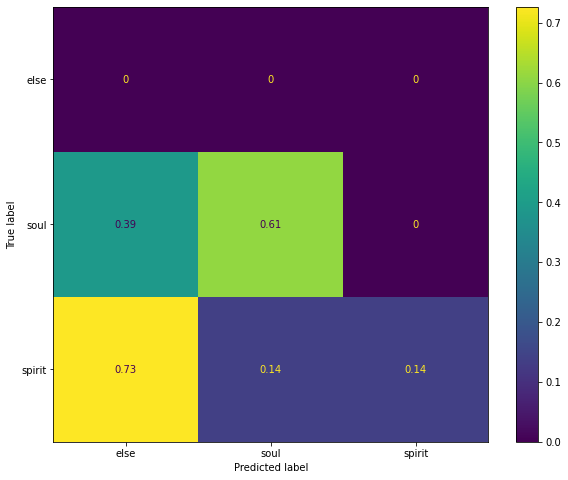
Now, let’s mask out the words soul and spirit and ask BERT to predict the missing word. If BERT mixes the two half the time, it means it thinks there is no distinction between them. Otherwise, they are probably distinct. The resulting confusion matrix:
The y axis represent the true word (soul or spirit), the x axis represents the predicted word (something else, soul or spirit). We can see that in more that 60% of the cases it predicts soul correctly. It never mispredicts it to spirit, but in 40% of the cases it does predict something else. For spirit, the results are worse: it predicts something else quite often, and on top of that, it predicts 50-50% between soul and spirit, so it mixes them up quite often.
The conclusion? The evidence is mixed: on one hand, usages of soul and spirit seem to be mostly different, because they cluster very neatly. But some key verses for the distinction are put in the soul cluster. Now, this might happen because of the way BERT extracts embeddings, two words that are in the same sentence will have similar embeddings. On the other hand, because of the way spirit is mispredicted, it would seem to indicate that there is significant overlap between spirit and soul, at least as “understood” by BERT.
Conclusion
I believe with some polish, BERT-style models can eventually make their way into the toolbox of someone who studies the Bible. They can offer a more consistent perspective to analyzing the text. And of course, they can be used not just to analyze the Bible, but for many other purposes, such as building tools for thoughts (using computers to help us think better and faster), or to analyze all kinds of documents, to cluster them, to extract information from them or to categorize them.
If you need help with that, feel free to reach out to me.
The full code for this analysis can be found in this Colab.
Text classification is a very frequent use case for machine learning (ML) and natural language processing (NLP). It’s used for things like spam detection in emails, sentiment analysis for social media posts, or intent detection in chat bots.
In this series I am going to compare several libraries that can be used to train text classification models.
The fastText library
fastText is a tool from Facebook made specifically for efficient text classification. It’s written in C++ and optimized for multi-core training, so it’s very fast, being able to process hundreds of thousands of words per second per core. It’s very straightforward to use, either as a Python library or through a CLI tool.
Despite using an older machine learning model (a neural network architecture from 2016), fastText is still very competitive and provides an excellent baseline. If you also take into account resource usage, it will be all but impossible to improve on the fastText results, considering that the only models that perform better require powerful GPUs.
Getting started with text classification with fastText
fastText requires the training data for text classification to be in a special format: each document should be on a single line and the labels should be at the start of the line, with the prefix __label__, like this:
Training data format
__label__sauce __label__cheese How much does potato starch affect a cheese sauce recipe?
__label__food-safety __label__acidity Dangerous pathogens capable of growing in acidic environments
__label__cast-iron __label__stove How do I cover up the white spots on my cast iron stove?
If you use Doccano for annotating the text data, it has an option to export the data in fastText format. But even if you used another tool for annotation, it’s only a couple of lines of Python code to convert to the appropriate format. Let’s say we have our data in a JSONL format, with each JSON object having a labels key and a text key. To convert to fastText format, we can use the following short snippet:
with open("fasttext.txt", "w") as output:
with open("dataset.jsonl", encoding="utf8") as f:
for l in f:
doc = json.loads(l)
labels = [x.replace(" ", "_") for x in doc['labels']]
labels = " ".join(f"__label__{x}" for x in labels)
txt = " ".join(l['text'].splitlines())
line = f"{labels} {txt}\n"
output.write(line)
Training text classification models with fastText
After you have the data in the right format, the simplest way to use fastText is through it’s CLI tool. After you installed it, you can train a model with the supervised subcommand:
> ./fasttext supervised -input fasttext.txt -output model
Read 0M words
Number of words: 16568
Number of labels: 736
Progress: 100.0% words/sec/thread: 47065 lr: 0.000000 avg.loss: 10.027837 ETA: 0h 0m 0s
You can evaluate the model on a separate dataset with the test subcommand and you will get the precision and recall for the first candidate label:
> ./fasttext test model.bin validation.txt
N 15404
P@1 0.162
R@1 0.0701
You can also get predictions for new documents:
> ./fasttext predict model.bin -
How to make lasagna?
__label__baking
Best way to chop meat
__label__food-safety
How to store steak
__label__food-safety
fastText comes with a builtin hyperparameter optimizer, to find the best model on a validation dataset, within the given time (5 minutes by default):
> ./fasttext supervised -input fasttext.txt -output model -autotune-validation validation.txt
If we reevaluate this model we’ll find it performs much better:
> ./fasttext test model.bin validation.txt
N 15404
P@1 0.727
R@1 0.315
A precision of 0.72, compared to 0.16 before. Not bad, for 10 minutes of our time, out of which 5 was waiting for the computer to find us a better model1Autotuning and performance evaluation should happen on separate datasets, to avoid overfitting, so real world performance is likely a bit worse than we got here.
Optimizing for different metrics
This library provides a couple of knobs you can use to try to obtain better models, from what kind of n-grams to use, how big the learning rate should be, what should be the loss function, but also what metric are you trying to optimize. Is precision or recall better aligned with your business KPIs? Is it more important to have the top result be a really good one or are you looking for several good results among in the top 5? Are you only interested in high confidence results? All this depends on the problem you are trying to solve and fastText provides ways to optimize for each of those.
Cons of fastText
Of course, fastText has some disadvantages:
Not much flexibility – only one neural network architecture from 2016 implemented with very few parameters to tune
No option to speed up using GPU
Can be used only for text classification and word embeddings
Doesn’t have too wide support in other tools (for deployments for example)
Conclusion
fastText is a great library to use when you want to start solving a text classification problem. In less than half an hour, you can get a good baseline going, which will tell you if this is a problem that is worth pursuing or not.
Data is crucial to any machine learning effort. And not just any data, but annotated data, so that the machine learning algorithms can learn what is the outcome it should predict. In some cases, we can get the data from some existing processes in the business, but more often than not, we need to set up a manual annotation process.
For annotating freeform text data (text generated by people) there is a great open source tool called Doccano. It is used to gather data for a wide range of common natural language processing (NLP) tasks, such as sentiment analysis, document classification, named entity recognition (NER), summarization, question answering, translation and others.
Text Annotation types
There are three kinds of data annotation types in Doccano.
Text classification
This kind of project enables you to annotate labels that apply to the entire document. For example, in a sentiment analysis task, you could label a document as being positive or negative. In a document classification task you will annotate what’s the topic of the document. You can choose multiple labels for each document.
Sequence Labeling
This is generally used for NER tasks, where you select relevant fragments from the text. For example, where are persons or organizations mentioned in documents. There can be several fragments selected for each document.
Sequence to Sequence
The Seq2seq annotation is for tasks such as summarization, question answering or translations from one language to another. There is a text box where you can write the appropriate response. For summarization, this would be the summary of the document. For questions, you can write several answers.
Setting up Doccano
Doccano offers 1-click installs for AWS, Azure and Heroku, or you can run it locally using Docker.
After you have Doccano running, you must create a new project and import your documents. Doccano is quite flexible and you can import data in multiple formats, such as plain text, CSV, JSONL or even fastText format.
You can create multiple users who will work on annotation. They can review each others work or they can annotate independently each document. In this case, the annotations from different labelers can be compared. If there are big differences, maybe the task is not clear and better guidelines are needed – if humans can’t solve the problem, machine learning won’t be able to solve it either.
Doccano features
Doccano is trying to make the annotation workflow as efficient as possible by giving keyboard shortcuts for most actions.
It has a dashboard where you can see statistics about how many documents were annotated, what’s the frequency of labels and how many documents were processed by each labeler.
You can also speed up the process by using an existing machine learning model to bootstrap the annotations. Either when uploading the data you specify some existing labels or you can configure Docanno to make a call to another REST API and get annotations from there. Then the labelers only have to review the output of the algorithm, instead of annotating from scratch.
Text Annotation Alternatives
There are other annotation tools as well. One for example is Prodigy, from the makers of Spacy, one of the most popular NLP libraries. It has a tight integration with Spacy and it has support for active learning, but it’s a paid product, unlike Doccano.
Another option is Label Studio, which supports annotating images, audio and time series, not just text.
If you need help setting up a text annotation pipeline to make sure that you are gathering the right data for your problem, don’t hesitate to contact me.
Machine learning (ML) has exploded in the last decade. Most companies try to apply ML in all kinds of areas, from image processing problems (such as recognizing defects in manufacturing), to forecasting, to trying to extract meaning from unstructured text, and many other problems. A quite common task is that of trying to classify documents into various classes. For example, you have many news articles and you want to group them by their topics, such as politics, entertainment, health, sports and travel. Another example would be a company that has many documents and wants to classify them by their type: invoices, resumes, various reports, and so on.
One of the big challenges of machine learning is that it requires a lot of annotated data. It’s not enough to just get a lot of news articles, a human has to go and annotate at least several thousands of them with their topic and only then can you start applying ML algorithms to solve your problem. In general, the more annotated data points you have, the better accuracy you get.
But getting the data is time-consuming and expensive. In some cases, you can crowdsource the data gathering, using a service such as Mechanical Turk, but in other cases, where more business domain knowledge is needed, the data annotation has to happen in house. If reading and classifying a document takes one minute, then annotating ten thousand documents will take 160 hours, so a month of full time work for someone. To ensure that your labels are accurate, because even human labelers make mistakes, the documents should be labeled by at least three humans. So the costs quickly go up.
SentenceBERT to the rescue
Recent developments in Natural Language Processing (NLP) research have led to the creation of neural networks that have a good understanding of language out of the box. One of them in particular can be used, with a clever reframing of the problem, to solve, or at least make it easier, our problem of text classification.
SentenceBERT is a followup to BERT, making it better by using siamese networks, and is used to generate sentence embeddings. None of this makes any sense? No problem, you don’t need to understand it to get started with it, but I’ll still try to explain the gist of it.
(For some reason, many models in NLP are named after Sesame Street characters: ELMo, BERT, Rosita, ERNIE, Grover, KERMIT, Big BIRD 😄)
Figure 1: BERT model
The problem SentenceBERT is trained to solve is Natural Language Inference (NLI), which consists of having two sentences, a premise and a hypothesis, and the model has to say what’s the relationship between those two sentences. Does the premise entail the hypothesis, are they neutral (unrelated) or are they contradictory? For example “A soccer game with multiple males playing.” entails “Some men are playing a sport.”, but “A man inspects the uniform of a figure in some East Asian country.” contradicts “The man is sleeping.”.
A side effect of trying to solve this problem is that SentenceBERT learns to “understand” sentences quite well. Understanding sentences is quite a philosophical debate, but what I mean by this is that it reduces a sentence (or even a paragraph) to a vector of numbers, such that sentences that are similar in meaning to each other have similar vectors assigned to them. These vectors are called embeddings and then can enable us to compare sentences.
How does this help us? Remember, we wanted to do text classification of single documents, not to figure out the relationship between two documents. Well, some clever researchers from the University of Pennsylvania have found a clever way to reframe one problem into the other.
Let’s say you want to classify news articles into topics such as politics, entertainment, health, sports, and travel. You take each topic and construct a sentence like “This text is about politics”. Now, this is a NLI problem: does the article entail our artificial sentence, which contains our topic?
It’s a very simple and incredible idea, but it turns out quite well in practice.
Let’s put it into practice
We are going to use the Transformer library from an awesome company called HuggingFace 🤗. They provide a pipeline that does all this for us, so it’s quite simple to use in 6 lines:
from transformers import pipeline
classifier = pipeline("zero-shot-classification", device=0)
sequence = "Who are you voting for in 2020?"
candidate_labels = ["politics", "public health", "economics"]
result = classifier(sequence, candidate_labels)
print(result)
And the output is:
{'labels': ['politics', 'economics', 'public health'],
'scores': [0.972518801689148, 0.014584126882255077, 0.012897057458758354],
'sequence': 'Who are you voting for in 2020?'}
In this simple example, the question “Who are you voting for in 2020?” was classified as being about politics with 97% probability, economics 1.4% probability, and public health as 1.2% probability, so it got this example correctly.
Running this requires a GPU and having all the libraries installed. It’s not hard to set up everything on your own computer, but it works better out of the box on Colab, a free environment Google provides for running Python notebooks in the cloud. You can even request to use a GPU in Colab. A more detailed notebook about this can be found here.
If you want to try it out even simpler, without having to mess around with notebooks, HuggingFace offers a demo on their website, where you just paste in different texts and the list of labels and it classifies them for you.
Other languages
All I presented above was for texts in English. But the same approach can work for other languages as well! There are pretrained models that are tuned for other languages, such as the xlm-roberta-large-xnli. This model supports 100 different languages, including Romanian. In general, results are best in the English language, because that’s where most of the data is (The XLM Roberta model was trained on 300 GB of English texts) and where most of the research has been focused, but even for Romanian language there is a dataset of 60Gb for training, so that should be enough getting things started.
When to use this
As I mentioned before, this is best run on GPUs. You can run it on CPUs, but it will be much slower (10-20 times slower). The more labels you have, the slower it is. It’s a quite complicated model, so it takes a lot of resources.
For text classification, there are many other models that are simpler, faster, and cheaper to run. But they have the disadvantage of requiring annotated data. If you have it, try to use those.
But if for example you are prototyping an idea for a startup and you don’t have annotated data yet, this approach is very good to get you started. In the beginning, you will not have many documents to classify anyway, so the fact that it’s slower is not too problematic, and it will help you quickly validate your idea. If it works, you can then invest in gathering annotated data and then switch to a simpler model.
Another way this model can help is by bootstrapping the annotation process. You have a large set of documents without labels, you run this model over them to generate labels, which might have only 50% accuracy. Then the human labelers only have to verify the suggested labels, thus speeding up the annotation process.
Conclusion
6 years ago, computer vision had it’s so-called “ImageNet” moment, when the challenge of labeling objects in images was “solved”. A new model was presented then which blew away all previous models. NLP is now getting closer to such a moment, with models such as SentenceBERT. In this article, I presented only how to use them for text classification, but they have many other use cases, such as finding similar articles, paraphrase mining, and so on.
A couple of years ago I was working on a calendar application, on the machine learning team, to make it smarter. We had many great ideas, one of them being that once you indicated you wanted to meet with a group of people, the app would automatically suggest you a time slot for the meeting.
We worked on it for several months. Because we wanted to do things like learn every users working hours, which could vary based on many things, we couldn’t just use simple hand-coded rules. In the end, we implemented this feature using a combination of both hand coded rules (to avoid some bad edge cases) and machine learning. We did lots of testing, both automated and manually in our team.
Once the UI was ready, we did some user testing, where the new prototype was put in front of real users, unrelated to our team, who were recorded while they tried to use it and then were asked questions about the product. When the reports came in, the whole team banged their heads against the desk: most users thought we were suggesting times when the meeting couldn’t take place!
What happened? If you included either many people or even only one very busy person, there will be no empty slot which is good for everyone. So our algorithm would make three suggestions, saying that for each there would be a different person who might not be able to make the meeting.
In our own testing, it was obvious to us what was happening, so we didn’t consider it a big problem. But users who didn’t know the system, found it confusing and kept going to the classic grid to manually find a slot for the meeting.
Lesson: machine learning algorithms are never perfect and every project needs to be prepared to deal with mistakes.
How will your machine learning project handle failures? How will you explain to the end users the decisions the algorithm made? If you need help answering these questions, let’s talk.
One of the most impressive/controversial papers from 2020 was GPT-3 from OpenAI. It’s nothing particularly new, it’s mostly a bigger version of GPT-2, which came out in 2019. GPT-3 is a much bigger version, being by far the largest machine learning model at the time it was released, with 175 billion parameters.
It’s a fairly simple algorithm: it’s learning to predict the next word in a text. It learns to do this by training on several hundred gigabytes of text gathered from the Internet. Then to use it, you give it a prompt (a starting sequence of words) and then it will start generating more words. Eventually it will decide to finish the text by emitting a stop token.
That’s amazing for such a simple approach. The internet was divided upon seeing these results. Some were welcoming our GPT-3 AI overlords, while others were skeptical, calling it just fancy parroting, without a real understanding of what it says.
I think both sides have a grain of truth. On one hand, it’s easy to find failure cases. It’s easy to make it say things like “a horse has five legs”, showing it doesn’t really know what a horse is. But are humans that different? Think of a small child who is being taught by his parents to say “Please” before his requests. I remember being amused by a small child saying “But I said please” when he was refused by his parents. The kid probably thought that “Please” is a magic word that can unlock anything. Well, not really, in real life we just use it because society likes polite people, but saying please when wishing for a unicorn won’t make it any more likely to happen.
And it’s not just little humans who do that. Sometimes even grownups parrot stuff without thinking about it, because that’s what they heard all their life and they never questioned it. It actually takes a lot of effort to think, to ensure consistency in your thoughts and to produce novel ideas. In this sense, expecting an artificial intelligence that is around human level might be a disappointment.
On the other hand, I believe there is a reason why this amazing result happened in the field of natural language processing and not say, computer vision. It has been long recognized that language is a powerful tool, there is even a saying about it: “The pen is mightier than the sword”. Human language is so powerful that we can encode everything that there is in this universe into it, and then some (think of all the sci-fi and fantasy books). More than that, we use language to get others to do our bidding, to motivate them, to cooperate with them and to change their inner state, making them happy or inciting them to anger.
While there is a common ground in the physical world, often times that is not very relevant to the point we are making: “A rose by any other name would smell as sweet”. Does it matter what a rose is when the rallying call is to get more roses? As long as the message gets across and is understood in the same way by all listeners, no, it doesn’t. Similarly, if GPTx can affect the desired change in it’s readers, it might be good enough, even if doesn’t have a mythical understanding of what those words mean.